

Cómo ejecutar un nodo Conflux
Conflux es una red totalmente descentralizada basada en PoW (prueba de trabajo). Si deseas participar en la minería de esta red descentralizada, o tener tu propio servicio RPC, necesitas ejecutar un Nodo (también llamado cliente). Este artículo te mostrará cómo ejecutar tu propio nodo de Conflux.
Nodo de archivos VS nodo completo
Hay 3 tipos de nodos Conflux: Nodo de archivos, nodo completo y el nodo ligero. La diferencia entre los tres tipos de nodos radica en la cantidad de datos reservados para el almacenamiento. El nodo de archivo toma más y el nodo ligero toma menos. Por supuesto, más datos consumen más recursos de hardware. haz clic aquí para obtener información detallada de los nodos.
En general, si deseas participar en la minería, un nodo completo será suficiente. Se necesita ejecutar un nodo de archivo si deseas utilizarlo como servicio RPC. El nodo ligero se utiliza principalmente como cartera.
Requerimientos de hardware
- CPU:
4 núcleos - Almacenamiento Interno: 16GB
- Disco Duro: 200GB
El nodo completo tiene un requisito de hardware más bajo y requiere una tarjeta gráfica básica si deseas participar en la minería.
Además, se recomienda que el número máximo de archivos abiertos se establezca en 10000. En Linux, el valor predeterminado es 1024, que es insuficiente.
Cómo obtener el programa y la configurar el nodo
Para obtener el programa de nodo de Conflux, puedes descargarlo en la página de lanzamiento en Github Conflux-rust oficial. Generalmente. Puedes descargar la última versión directamente. Cada versión no solo contiene el código fuente, sino que también proporciona programas de nodo compilados para Windows, Mac y Linux.
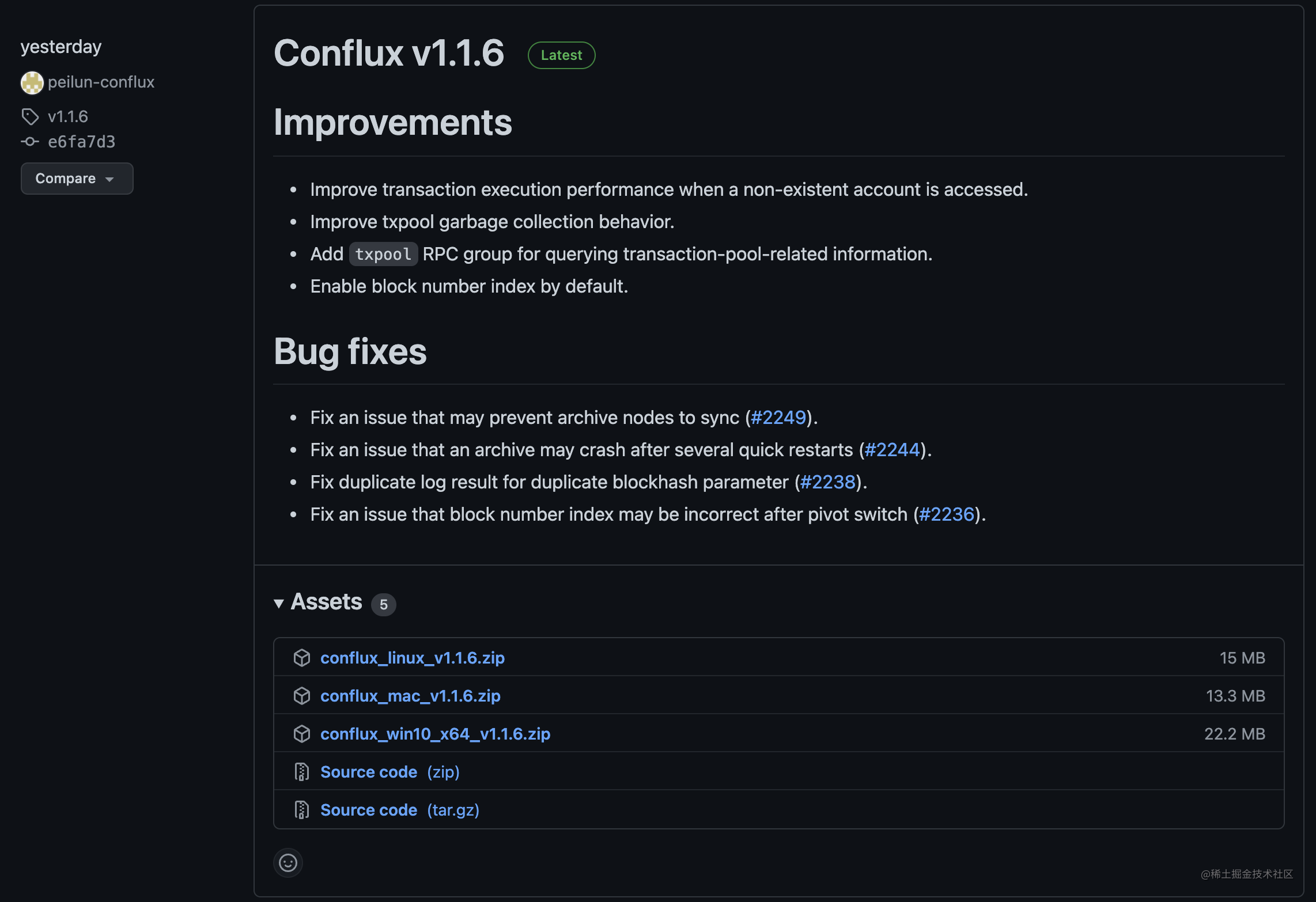
Atención: En este momento hay dos líneas de versión: Conflux-vx.x.x para la red principal y Conflux-vx.x.x-testnet para la red de prueba. Debes seleccionar la versión correcta de acuerdo con tus necesidades cuando descargues el programa.
El archivo comprimido que descargas se puede descomprimir en una carpeta de ejecución, que contiene el siguiente contenido:
➜ run tree
.
├── conflux # programa del nodo
├── log.yaml # archivo para la configuración de registros
├── start.bat # script de inicio en windows
├── start.sh # script de inicio en sistemas unix
├── tethys.toml # archivo de configuración para la red principal
└── throttling.toml # archivo de configuración para el límite de trafico
0 directories, 6 files
Hay 2 archivos a los que debes prestar atención: conflux y tethys.toml. Si descargas el paquete de Windows, el programa de nodo ejecutable debería ser conflux.exe.
Otra forma de obtener el programa de nodo es compilar el programa de nodo a partir del código fuente, si estás interesado en hacerlo, haz clic aquí.
Configuración
Debes preparar el archivo de configuración del nodo antes de ejecutar el programa del nodo. Puedes encontrar el archivo de configuración en el paquete del programa descargado. Generalmente, el archivo de configuración de la red principal es tethys.toml y el archivo de red de prueba es testnet.toml. La principal diferencia entre los dos archivos de configuración son los valores de configuración de bootnodes y chainId. Los desarrolladores también pueden buscar los archivos de configuración en el directorio de ejecución del repositorio conflux-rust de Github. El nombre del archivo también es [tethys.toml](https://github.com/Conflux-Chain/conflux-rust/blob/master/run/tethys.toml) o testnet.toml.
Por lo general, el usuario no necesita cambiar ninguna configuración, simplemente ejecutar la secuencia de comandos de inicio (si no deseas conocer los detalles de la configuración, puedes pasar a la siguiente sección para aprender a ejecutar el programa de nodo). Sin embargo, si deseas abrir la función determinada o establecer algunos comportamientos definidos por el usuario, debe establecer algunos parámetros de configuración. Las siguientes son algunas de las configuraciones más comunes:
tipo_nodo
-
node_type:se utiliza para establecer el tipo de nodo, puedes seleccionarfull(predeterminado),archive,light.
chainId
-
chainId: se usa para establecer el ID de la blockchain a conectarse, el valor de la red principal es 1029, el valor de la red de prueba es 1 (generalmente, no es necesario cambiarlo).
Relacionado con la minería
-
mining_address: la dirección para recibir la recompensa minera. Puedes configurar la dirección hex40 o la dirección CIP-37 (nota: el prefijo de red de la dirección debe coincidir con el chainId configurado actualmente). El valor predeterminado demining_typeesstratum -
mining_type: los valores opcionales sonstratum,cpu,disable. -
stratum_listen_address: dirección de stratum -
stratum_port: número de puerto de stratum -
stratum_secret: credencial de conexión de stratum
Relacionado con el RPC
-
jsonrpc_cors: se utiliza para controlar la validación del dominio RPC. Los valores opcionales sonNone,allo nombres de dominio separados por comas (sin espacios). -
jsonrpc_http_keep_alive:falseotruese usa para controlar si se configura KeepAlive para conexiones HTTP RPC. -
jsonrpc_ws_port:número de puerto RPC de websocket. -
jsonrpc_http_port:número de puerto http RPC. -
public_rpc_apis: configuración de api de RPC de acceso público, los valores opcionales sonall,safe,cfx,debug,pubsub,test,trace(safe = cfx + pubsub). El valor recomendado essafe. -
persist_tx_index:trueofalse. Si necesitas procesar RPC relacionados con transacciones, debes abrir esta configuración al mismo tiempo; de lo contrario, solo podrás acceder a la información de transacción más reciente.
-persist_block_number_index:trueofalseSi deseas buscar la información del bloque por blockNumber, debes establecertrue. -
Executive_trace:trueofalse. Indica si se abre la función de ejecución de seguimiento de EVM. Si está habilitado, el rastreo se registrará en la base de datos. -
get_logs_filter_max_epoch_range: el registro de eventos se obtiene llamando acfx_getLogs, que tiene un impacto significativo en el rendimiento del nodo. El rango máximo de la época que se puede buscar se configura a través de esta opción. -
get_logs_filter_max_limit: número máximo de registros en una sola consulta porcfx_getLogs.
Captura Instantánea (Snapshopt)
-
additional_maintained_snapshot_count: se utiliza para establecer el número retenido de instantáneas antes de establecer el punto de control estable, el valor predeterminado es 0. Se eliminará la instantánea anterior a la génesis estable. Esta opción es necesaria si el usuario desea consultar un estado histórico más distante. Cuando esta opción está activada, el uso del disco aumentará considerablemente.
Directorios
-
conflux_data_dir: el directorio de almacenamiento de los datos (datos de bloque, datos de estado, base de datos de nodo). -
block_db_dir: el directorio de almacenamiento de los datos del bloque. De forma predeterminada, se almacena en el directorio blockchain_db en el directorio especificadoconflux_data_dir. -
netconf_dir: se usa para controlar los directorios persistentes relacionados con la red, incluyenet_key.
Relacionado con el registro
-
log_conf: se utiliza para especificar los archivos de configuración de registro comolog.yaml, la configuración en el archivo de configuración sobrescribirá la configuración de nivel de registro. -
log_file: ruta del registro. Si no está configurado, el registro se enviará a stdout. -
log_level: nivel de impresión del registro, los valores opcionales sonerror,warn,info,debug,trace,off.
Cuanto más alto es el nivel de registro, más registros se generan, lo que ocupa más espacio en la memoria y afecta el rendimiento del nodo.
Modo desarrollador (dev)
Los desarrolladores de smart contracts, que quieran implementar y probarlos en un entorno de nodo local, pueden usar este patrón:
- Comenta la configuración de
bootnodes -
mode: establece el modo de nodo endev -
dev_block_interval_ms: el tiempo del intervalo de generación del bloque, la unidad es ms.
En este modo, ejecutarás una red de un solo nodo con todos los métodos RPC abiertos.
Configuración de cuentas de Genesis
Puedes configurar una cuenta de genesis utilizando un solo archivo genesis_secrets.txt en el modo de desarrollo. Este archivo requiere una línea para colocar una clave privada (sin el prefijo 0x). Debes agregar genesis_secrets al archivo de configuración y establecer el valor en la ruta del archivo:
genesis_secrets = ‘./genesis_secrets.txt’
Después de que comiencen los nodos, cada cuenta comenzará con 10,000,000,000,000,000,000,000 Drip, es decir, 10k CFX.
Otro
-
net_key: es una clave privada de 256 bits que se utiliza para generar un ID de nodo único. Esta opción se genera aleatoriamente si no está configurada. Si deseas configurarlo, puedes completar 64 caracteres hexadecimales. -
tx_pool_size: el número máximo de transacciones que se pueden almacenar (por defecto500k) -
tx_pool_min_tx_gas_price: el límite mínimo para el comercio de gas Precio por grupo de negociación (predeterminado1)
Para una configuración completa, puedes consultar el archivo de configuración, que contiene todos los elementos configurables y comentarios detallados.
Iniciar el nodo
Una vez que el archivo de configuración está habilitado, puedes ejecutar el nodo a través del programa de nodo.
# Ejecutar el script de inicio
$ ./start.sh
Si ves un contenido como este en la salida estándar o en el archivo de registro, el programa de nodo se ha iniciado correctamente:
2021-04-14T11:54:23.518634+08:00 INFO main network::thr - throttling.initialize: min = 10M, max = 64M, cap = 256M
2021-04-14T11:54:23.519229+08:00 INFO main conflux -
:'######:::'#######::'##:::##:'########:'##:::::::'##::::'##:'##::::'##:
'##... ##:'##.... ##: ###:: ##: ##.....:: ##::::::: ##:::: ##:. ##::'##::
##:::..:: ##:::: ##: ####: ##: ##::::::: ##::::::: ##:::: ##::. ##'##:::
##::::::: ##:::: ##: ## ## ##: ######::: ##::::::: ##:::: ##:::. ###::::
##::::::: ##:::: ##: ##. ####: ##...:::: ##::::::: ##:::: ##::: ## ##:::
##::: ##: ##:::: ##: ##:. ###: ##::::::: ##::::::: ##:::: ##:: ##:. ##::
. ######::. #######:: ##::. ##: ##::::::: ########:. #######:: ##:::. ##:
:......::::.......:::..::::..::..::::::::........:::.......:::..:::::..::
Current Version: 1.1.3-testnet
2021-04-14T11:54:23.519271+08:00 INFO main conflux - Starting full client...
Una vez iniciado el programa de nodo, se crean dos carpetas nuevas blockchain_data y log en el directorio de ejecución. Se utilizan para almacenar registros y datos de nodos.
Después de iniciar una nueva red principal o un nodo de red de prueba, sincronizarás los datos de bloques históricos de la blockchain, y los nodos que se están poniendo al día están en modo decatch up. Puedes ver el estado del nodo y el último recuento de época en el registro:
2021-04-16T14:49:11.896942+08:00 INFO IO Worker #1 cfxcore::syn - Catch-up mode: true, latest epoch: 102120 missing_bodies: 0
2021-04-16T14:49:12.909607+08:00 INFO IO Worker #3 cfxcore::syn - Catch-up mode: true, latest epoch: 102120 missing_bodies: 0
2021-04-16T14:49:13.922918+08:00 INFO IO Worker #1 cfxcore::syn - Catch-up mode: true, latest epoch: 102120 missing_bodies: 0
2021-04-16T14:49:14.828910+08:00 INFO IO Worker #1 cfxcore::syn - Catch-up mode: true, latest epoch: 102180 missing_bodies: 0
También puedes usar cfx_getStatus para obtener el número de época más reciente del nodo actual y compararlo con la última época del explorador de conflux para saber si los datos se han sincronizado.
Servidor RPC
Una vez que se inicia el nodo, si se abres el puerto relacionado con RPC y se habilitan las configuraciones, las carteras y Dapps pueden acceder al nodo a través de la URL de RPC. Por ejemplo:
http://ip-nodo:12537
Esta dirección se puede utilizar al agregar redes a ConfluxPortal o SDK.
Ejecuta el nodo usando Docker
Si estás familiarizado con Docker, puedes usar Docker para ejecutar un nodo.
Las versiones oficiales de la https://github.com/conflux-chain/conflux-docker pueden ser extraídas y ejecutadas.
Dado que los datos del nodo son grandes, se recomienda montar un directorio de datos para almacenar los datos del nodo cuando se ejecuta la imagen.
hay tres pipelines para la etiqueta reflejada:
-
x.x.x-mainnet: red principal -
x.x.x-testnet: red de prueba -
x.x.x: modo desarrollador. En este modo, diez cuentas se inicializan automáticamente para el desarrollo local.
PREGUNTAS FRECUENTES:
¿Por qué la sincronización tarda mucho después del reinicio?
Una vez que se reinicia un nodo, sincroniza los datos del último punto de control y reproduce los datos del bloque. Tomará diferentes cantidades de tiempo según la distancia hasta el último punto de control. Después de eso, comenzará a sincronizarse desde el último bloque.
Es normal, por lo general, tardará entre unos minutos y más de diez minutos.
¿Por qué deja de aumentar la altura del bloque?
Si la altura del bloque deja de aumentar, puedes verificar el registro o el terminal para determinar si hay algún error. Si no hay ningún error, lo más probable es que se deba a razones de red, puedes intentar reiniciar el nodo.
Una vez modificada la configuración, ¿debo borrar los datos al reiniciar el nodo?
Dependiendo de la situación, a veces lo tienes que hacer, a veces no. Si la configuración implica un almacén de datos o un índice de datos, debes reiniciar el nodo si la configuración cambia, por ejemplo:
persist_tx_indexexecutive_tracepersist_block_number_index
Por lo general, no se requieren otros reinicios.
¿Cuál es el tamaño de los datos del nodo de archivo actual?
Hasta 2021.11.04, el tamaño del paquete de compresión de datos en bloque es inferior a 90 GB
¿Cómo involucrarse en la minería?
La minería requiere GPU, puedes ver aquí para obtener más detalles
¿Cómo sincronizar datos rápidamente para ejecutar un nodo de archivo?
Puedes usar fullnode-node para descargar la instantánea de datos del nodo de archivo, los datos del nodo se pueden sincronizar rápidamente con los datos más recientes mediante una instantánea.
Cómo comprobar el registro de errores
Si ejecutas el nodo a través de start.sh, puede verificar el registro de errores en stderr.txt en el mismo directorio.