
本贴内容主要针对win10系统,其他系统如果存在的其他问题(类似的问题可以用相同手段尝试处理),可在本贴按第三大项进行操作。
一、一般故障
1.同步状态、挖矿状态中,epoch:xxx一直不动,卡住了,怎么办?
解决方案一:
等待三十分钟。(如果epoch:xxx的数值依然没有增加,请使用解决方案二。)
解决方案二:
重启挖矿程序。(三十分钟后,如果epoch:xxx的数值依然没有增加,请使用解决方案三。)
解决方案三:
(1)关闭挖矿程序。
(2)删除四个同步数据文档。

(3)启动挖矿程序。
(4)等待三十分钟。(如果epoch:xxx的数值依然没有增加,可参照本贴下方,第三大项,非一般故障,向官方反馈的操作流程,进行操作。)
二、一般故障说明(此专题皆为官方技术人员回复)
1.为什么会发生上述情况?
这个版本卡的主要原因是最近GFW墙变高了,导致很多官方部署在境外的服务器(全信息超级节点)连接不上。
在专业角度上,根据反馈的日志来看,是“黑名单”相关的问题,不过这个问题主要是由于其他节点响应太慢导致timeout,你本地的节点会把它们临时放进黑名单,然后最终所有节点都被放进黑名单导致你本地的节点不再连接任何节点了,然后就不再同步了。重启会重新连接配置文件里的bootnodes,所以能够部分解决这个问题。
2.什么是“临时黑名单”?
这个“临时黑名单”的说法不太准确。在此详细说下,可连接的节点会被自己分为分为信任、不信任、黑名单三种状态,信任的节点是在断连之后我主动去连的;不信任是断连之后不主动连,但是如果对方主动连我的话我也会接受;黑名单是对方主动连我也会拒绝。网络连接问题反复出现的话会把节点放到不信任(刚才说的临时黑名单)的状态下,然后断开连接,所以这个是不会主动恢复的。黑名单的节点在一段时间之后变成不信任的状态(貌似1周左右),不信任的节点在对方主动连接之后持续一段时间(好像也是一周)会重新变成信任状态。现在的问题就是所有节点都变成不信任的状态,而且也没有人来主动连你,你就全部断连了。我们应该需要在这种情况所有邻居都断开的情况在屏幕上输出一下说明。
3.为什么会出现,一个人挖出一颗“区块链子树”?
挖矿中,卡区块应该还是同一个问题,就是所有连接都断开了的状态。false可能是因为最后断开的那个连接也是一个还在同步的节点,你同步到了它的最新状态之后就变false了。
根据BUG反馈信息来看,还是不同的区块,哈希值不同。估计是在断开连接的期间挖了几百个区块,然后又连回去了,导致这些区块被主链打包在同一个纪元里。
4.为什么每次epoch:xxx提升5w,会出现一段时间的cpu占用率飙升?
每5w可能出现一段时间CPU飙升,是因为程序在做checkpoint(建立检查点/存档点)。
5.有改进方案吗?
拟定改进方案如下:
(1)增加境内超级节点(全信息节点)数量。
(2)下个版本可能会有“临时黑名单”配置功能(可开关)。
(3)排查节点响应太慢是否都是由于网络问题。
三、非一般故障,向官方反馈的操作流程
如果删除全部数据重启还是有问题的话,请进行如下操作。(为您的贡献,表示真挚的感谢。)
1.以记事本模式打开log.yaml,loggers以下的info都改成debug后,保存并退出。
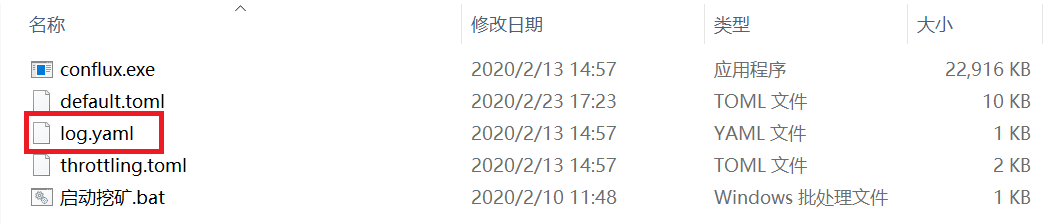

2.运行挖矿程序,十分钟至二十分钟后关闭挖矿程序。
3.把log文件夹做成压缩包,上传至百度云盘,做成分享链接。
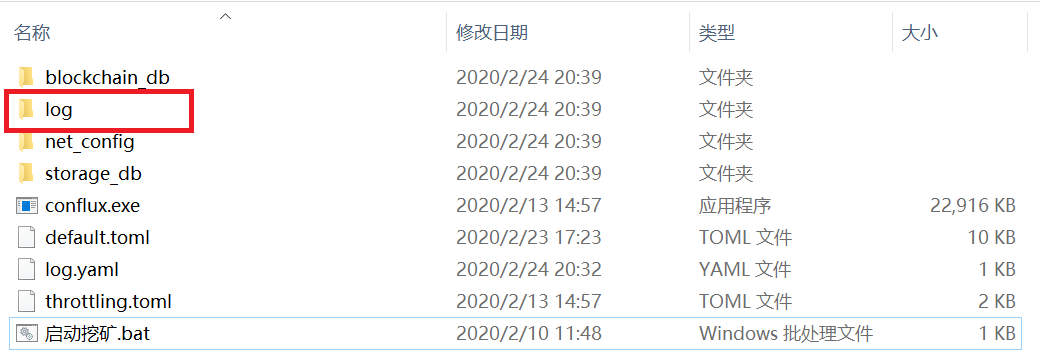
4.将百度云分享链接发送至本贴回复栏。